Clustering and high availability
Exinda Appliances can be seamlessly deployed into high availability and load balanced network architectures. The Exinda clustering options allows multiple Exinda Appliances to be deployed into these architectures and to operate as if they were a single appliance. A typical deployment topology is illustrated below.
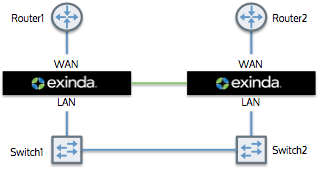
A typical clustering topology.
In this example, there are two physical links: from Router1 to Switch 1 and from Router2 to Switch2. An Exinda appliance is deployed between each switch and router, and a cable is connected between the two appliances for synchronization.
The appliances share configuration, monitoring information, and optimizer policies, as if they were a single appliance. For the purposes of configuration synchronization, one appliance is considered as the master appliance, the other appliance(s) are the slaves. The master appliance shares its configuration with the slaves.
Once the appliances are configured, the appliances will auto-discover each other and one will be elected as the Cluster Master. All configuration must be done on the Cluster Master, so when accessing the cluster, it is best to use the Cluster Master IPInternet protocol address when managing a cluster.
CAUTION
When upgrading the firmware of appliances that are part of a cluster, Exinda recommends that you break the cluster before starting the upgrade (Either by disconnecting the cluster link or by clearing the “Cluster” option for the appropriate interface). After all appliances in the cluster have been upgraded to the same firmware, the cluster can be put back together.
IMPORTANT
Appliances in a cluster must be the same model and have the same number of bridge pairs. The time on all the appliances must use NTPNetwork Time Protocol to ensure that all appliances have exactly the same time.
Shared Configurations
As part of normal cluster operations, the Cluster Master synchronizes parts of the system configuration to all other nodes in the cluster. Some configuration is specific to an individual appliance (for example IP addressing and licensing), however, most of the system configuration is synchronized throughout the cluster, including:
- Optimizer Policies (see note below)
- Network Objects
- Protocol and VLAN Objects
- Applications and Application Groups
- Optimizer Schedules
- Monitoring and Reporting Settings
- SDP and Remote SQL Settings
- Time-zone and NTP Settings
- Logging Settings
- Email and SNMPSimple Network Management Protocol Notification Settings
NOTE
Optimizer policies are also implemented globally across all cluster nodes. For example, if there were a single policy to restrict all traffic to 1Mbps, this would be applied across all cluster nodes. So, the sum of all traffic through all cluster nodes would not exceed 1Mbps.
Shared Monitoring Information
All appliances in the cluster can be monitored. Most monitoring information is shared across the cluster. Some reports don’t make sense to share (e.g. Interface reports); however, most reports are synchronized, including:
- Realtime
- Network
- AQS
- Applications and URLs
- Hosts
- Conversations
- Subnets
NOTE
When monitoring information is shared across the cluster, the timestamp on this information is not shared across the cluster. New timestamps are added to the data when it enters the other appliances in the cluster. If there is a delay in sharing this information, which could be due to the appliances in the cluster being separated physically by a great distance or by not providing enough bandwidth between the clustered appliances, the reports may not appear similar on the different appliances in the cluster.
When a cluster node fails
In the event that a node in the cluster fails, is rebooted, or powered off, bypass mode is enacted and traffic passes though unaffected. When the appliance comes back online, the node is updated with the latest configuration settings from the Cluster Master and normal operations resume. Monitoring and reporting information during the downtime is not synchronized after the fact.
In the event that the Cluster Master fails, is rebooted, or powered off, a new Cluster Master is automatically elected. The offline node (previously the Cluster Master) is treated as a regular offline node. When it comes back online, it does not necessarily become the Cluster Master.
Cluster Terminology
| Term | Meaning |
|---|---|
| Cluster | A group of Exinda appliances (cluster nodes) configured to operate as a single Exinda appliance. |
|
Cluster External IP |
An IP address assigned to the management port of the cluster master. Whichever node is the cluster master has this IP address assigned to its management port. |
| Cluster Node | An Exinda appliance that is a member of a cluster. |
| Cluster Interface | The physical interface that a node in the cluster uses to connect to other cluster nodes (also referred to as the HA or AUX interface). |
| Cluster Internal IP | A private IP address assigned to each cluster node that enables communication with other nodes in the cluster. |
| Cluster Master |
The node responsible for synchronizing configuration changes with all other cluster nodes. The cluster master is automatically elected. Configuration changes should only be made from the cluster master. |
| ID |
The cluster-assigned unique identifier for each node. |
| Management IP | The cluster management (alias) address. The cluster is always reachable at this address as long as at least one node is online. |
| Role | The current role of a given node within the cluster (master or standby). |
| State | The state (online or offline) of a given node. |